Graphing Legalese
Boy, was I wrong.
The cumbersome legal jargon is one thing. It's expected, and most of it I can muddle through with a dictionary on one side - although god knows what 'notwithstanding' means in any legal context whatsoever. The general topic comes through, if not the particulars. No. The truly oppressive problem comes from sections sagging under the strain of self-reference. Consider this particularly offensive situation:
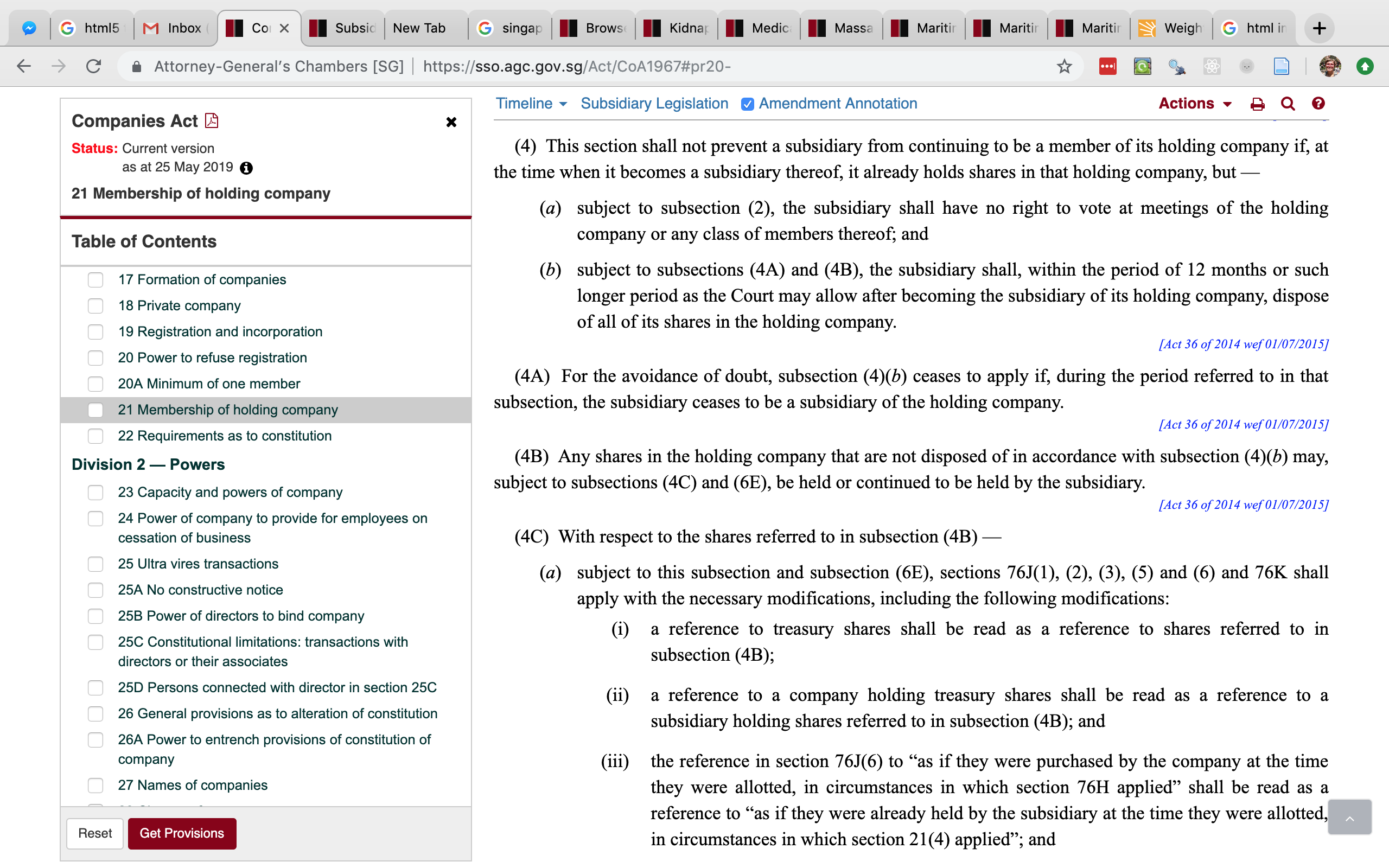
This is representative of most laws, which don't exist as one coherent consecutive document but rather a collection of ties and references. In order to properly understand this section, I need to consult twenty others. Fair, half of those are available on the same screen, but I need to open and search in several other tabs to make sense of anything. It makes me want to pin up the Act page by page with bright red yarn to highlight the links, like one of those crazy-people corkboards.
It would be so much easier if a couple of quick clicks could open the relevant dependencies next to the current section, on the same page. This would be quick and easy to consult, so this Act could be read all in one go. Same effect as the corkboard in a bit less space. I've looked around and haven't been able to find anything currently out there that does this. Here's a quick mockup to show you what I'm talking about:

General Considerations:
Intentions: I'm not in this to build production-level software, or really focusing at all on performance. The product should be convenient for my personal use, and be good-looking and intuitive for anyone who happens across it. A personal tool that doubles as a showpiece, built using easily accessible resources. My other goals are around the development process, which should improve my coding knowledge without becoming overwhelming, and only use immediately available resources.Right now I'm building out this website and improving my JavaScript, so that gives me an immediate framework for a webpage; hosted by GitHub, built with Jekyll, coded in JS (and affiliates). This is a kinda terrible setup. This is a static website, GitHub pages have limited capacity, and JS isn't exactly a highly performant language. So most likely, in order to view a connected document, the user will process all the analytics and data structuring client-side on page load, each and every time. Perhaps at a later date I'll work on storing data structures as they're built, but for now I'm just shrugging my shoulders at the gross inefficiencies knowingly enshrined in this system.
Input data: The initial system will be based on Singaporean Law, which is relevant to me, pretty standardized, and helpfully available at Singapore Statutes Online (SSO) . However, the general presentation and back end should be easily extensible to other forms of self-referential (legal) documents, with as minimal a modular change as possible. Singaporean law is generally divided up into hierarchical pieces like so:
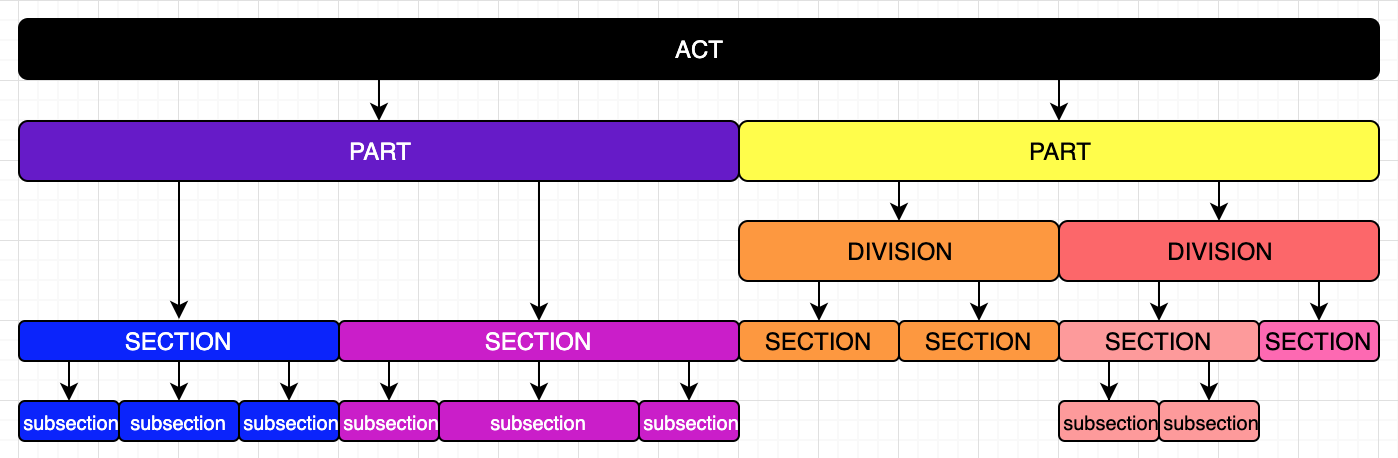
Subsections are the smallest self-contained element. They sometimes include lists, but the list items generally aren't complete statements on their own. Sections are the key element. As the diagram shows, an Act doesn't always have the divisions or subsections layers at every path - but it must have sections.
References: We can call these directed edges or links. Sections typically reference sections or subsections. More rarely, they reference a particular list item of a subsection, or an entire other Act. References to list items will be taken as references to the encapsulating (sub)section. Within the general database of Singaporean law, I've identified four main types of reference:
- Definitions: Most legal documents will have an 'interpretation' section which subsequent uses of terms depend on.
- Internal to Section: Subsections often cite other subsections under the same section.
- Internal to Act: Citing a (sub)section in the same Act, but not the same section.
- External Act: An Act can depend on other pieces of legislation, eg: The Companies Act refers to the Accountants Act.
Development Stages:
Personally, I see this project dividing into three main parts.
These are divided on the basis of both task and materials. Each stage has a fairly modular purpose, and each will use different tools. The first will involve requesting and parsing html with a sprinkling of RegEx, the second some thought to appropriate data structures, and the last some thought to UX and markup implementation.
Each successive stage depends on the prior ones. I can't display links or other things I haven't represented in my data structures, and my structures can only contain whatever information's extracted at the parsing stage. Since the main goals of this project are achieved at the display page, I'll think about that first. Then, when planning the other stages, I'll know what I want to provide.
Display
Base document. First, lets think of the basics. How is the meat of the document shown? We saw my first, basic, mockup earlier. It keeps the general layout of the government website, with the table of contents at the left and the Act as a sequential stream in the middle. Another way of doing this would be to put the focus on representing the Act as interlinked nodes, with the references taking precedence over the neighbors. The next mockup centers around the current subsection, with the appropriate links showing up around it. The preceding and succeeding subsections don't turn up at all - they can be accessed with the back and forward arrows, or you can skip to a different section with the dropdown.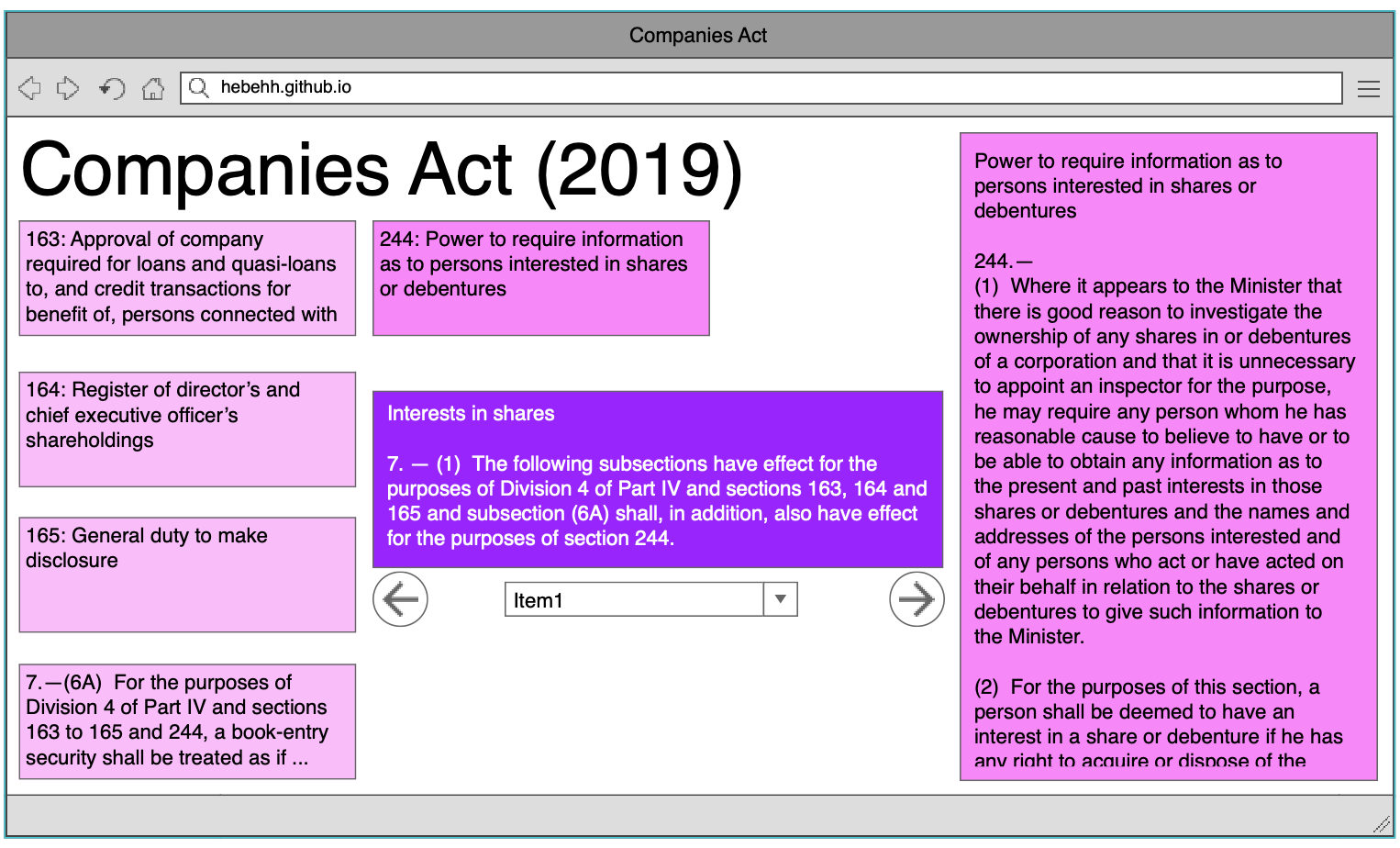
These are very different approaches. The first expects that neighbouring sections will be relevant to each other, while the second depriortizes that relevance. The general method of interaction also changes. In the former, you can immediately skim the text. Jumping to a section is very possible with the side menu, but the immediate mode of interaction is sequential. The second display puts jump access on par with sequential access.
Intuitively, neighbouring sections are thematically similar. Glancing across various laws supports this, and further shows that most links are of the second type - to another subsection of the current section. Also, I personally think skimming a quick scroll is a useful way to interact with this kind of document. Thus I'll go with the first type of display.
Links. So far I've basically decided to reproduce the SSO format. Okay, that's fine, but I want to extend that. My first mockup does show with buttons beside the main text that bring up a panel of linked text when clicked. The given example looks functional - but it's sweeping a couple of issues under the rug.
- Space: The section of main text you're looking at might have multiple links and/or particularly large ones. How to fit that all on the screen? Is it better to restrict the amount of links available? What if the link is just too large to reasonably show as a new panel - a link to an entire Division, or a different Act?
- Recursion: What happens when a link links to other (sub)sections? Can you only go down one layer, or further? If further, where do you display the next layer of dependencies? Again, space issues. How to indicate where the links are?
- Local links: The second kind of reference I identified were internal to the section. These are pretty common. Given that I'm displaying the main text sequentially, it's probable that many of the links will point to subsections that are already visible in the window. Here, is it better to stick to form and just give the button and panel, or somehow direct the user to the text already available?
- Text highlighting: The buttons at the side is a nice way to give the links, sure, and probably easier to code - but the UI might be better if the links are part of the text directly, or at least the relevant text is highlighted. This would be particularly useful for the first kind of reference, to the meanings of words or phrases.
Metadata. As well as the direct links, there's the possibility of showing summary data for each clause and the Act itself. For instance:
- Are there any cycles in the dependency chain?
- How many dependencies does a clause have? On the first level, or all the way down the dependency tree? Density of references throughout the Act?
- What sections are referred to the most? This might be a good metric for importance.
- Which definitions are used the most? Are any not used at all?
- What sections are highly self-referential? Which link to separate sections?
- How much of a clause is written elsewhere?
- etcetera, more will come up as we go.
Data Structures: Representing an Act.
As before, the basic component of an Act is the (sub)section. We're combining these in two ways. First, there's the stringently ordered fashion of the actual Act, where consecutive sections are grouped appropriately into divisions and parts for sequential reading. Next, there's the link from one node to another caused purely due to an internal reference, which isn't restricted by the orderly structure of the document. Let's consider the (sub)sections as nodes. How to best relate these for our two purposes?Main text: Two ways immediately came to mind to represent the structure of the document; trees and lists of lists. Hell, glancing at the diagram I made earlier of the hierarchy of an Act, it looks like a tree. It is a tree. Lists of lists have some similar properties. In this situation, the difference I'd focus on is that a tree is useful when the focus is on the child/parent relationships, while lists are more focused on sibling relationship. Importantly, the order of same-level elements is integral to lists of lists, but not to trees. While most trees have a general concept of right/left nodes, that doesn't always carry to non-binary flora. Generally, since order is important to this part, I'm leaning towards lists of lists.
This is kinda complicated by the fact that not every layer is populated. In the Companies Act, the first two Parts don't have divisions, but the rest do. This adds complexity in the representation of the hierarchy, because now I can't assume the type of the child of a Part (tree) or comfortably represent a Part as a list of Divisions (list of lists).
Links: So lets turn to the other aspect - links - and see if they'll influence either way. Straight off, this seems like a good task for a graph. Like, the definition of a graph. Since I'm expecting the links to be relatively sparse compared to the possibility space, I'm thinking Adjacency List format, unless JS has a particular library that's more useful or user-friendly.
Building the graph requires finding the edges. This somewhat veers into parsing stage territory, but not really. Let's assume we've managed to extract all sections and subsections, and for each, any link to another (sub)section. How do we find the target?
- Definitions: A word or phrase in the clause that was defined earlier. Must find the clause that specifically defined this.
- Internal to Section: Formatted like "subsection (x)". Find by going to parent section of current subsection, then going to subsection (x)
- Internal to Act: Formatted as either "section A" or "subsection A(x)". Find by going to section A, and if necessary subsection (x) of A.
Yeah, no. They're ordered, sure, but the step varies. Section 2 may be followed by section 2A, 2B and 2C before section 3 turns up. Goddamn. So we want a dictionary. On the other hand, the section numbering is ordered. It might actually be quicker to stick to the list idea, then binary search to find the right key.
So how do we store everything to make building links easier? Sections should be ordered. There should be a strong parent/child relationship between subsections and sections. And we don't care about parts, or divisions, or really any other layer.
Overall, I'm currently leaning strongly towards a list of sections, which contain a list of subsections (if applicable). Each subsection object should also contain a reference to it's parent section. This should make it easy to both display the Act as a whole and build an adjacency list graph representation of the links between clauses.
Data Parsing:
This was meant to be the dumb-as-pie part to start, with an input document given as a string or .txt file. Then each new line would signal a new section, with hardcoded RegEx to find section numbers and references. Wouldn't necessarily work past the one input, but I felt I could extend it with extra modules later. Then I realized what a damn trove of treasure the SSO website is.Pretty much every Singaporean law can be curl'd in full off the web. This isn't precisely straightforward, since the whole Act doesn't turn up on the firl GET. Instead, you get the first few clauses and the table of contents. The table of contents HTML, however, has the internal reference codes you need to add to the URL to get each subsequent section.
This gives you a bunch of HTML code, in a somewhat predictable structure for JS's DOM access calls to extract every (sub)section. From there, everything can be plonked into the finalized data structure before RegExing out the internal references.